engagement depth
More than a project screenshot: what the work proves.
The value of selected work is strongest when it shows the connection between architecture choices, business pressure, implementation quality, and leadership confidence.
Architecture decisions connected to commercial or operational pressure
Technical leadership that clarifies ownership and sequencing
Implementation work shaped around measurable delivery outcomes
Scalable execution patterns that remain useful after launch
Decision context
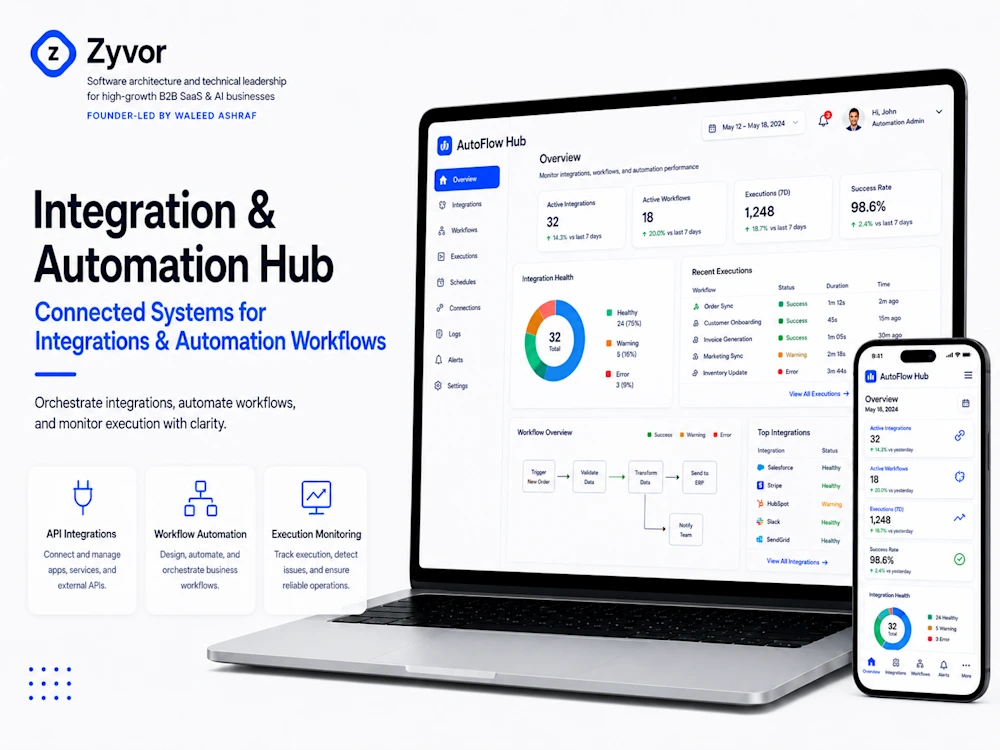
The conglomerate had 40 tools and zero system of record. Every number was a guess until someone spent days reconciling it. That business pressure shaped the architecture choices, implementation order, and operating model behind the work.
Delivery leverage
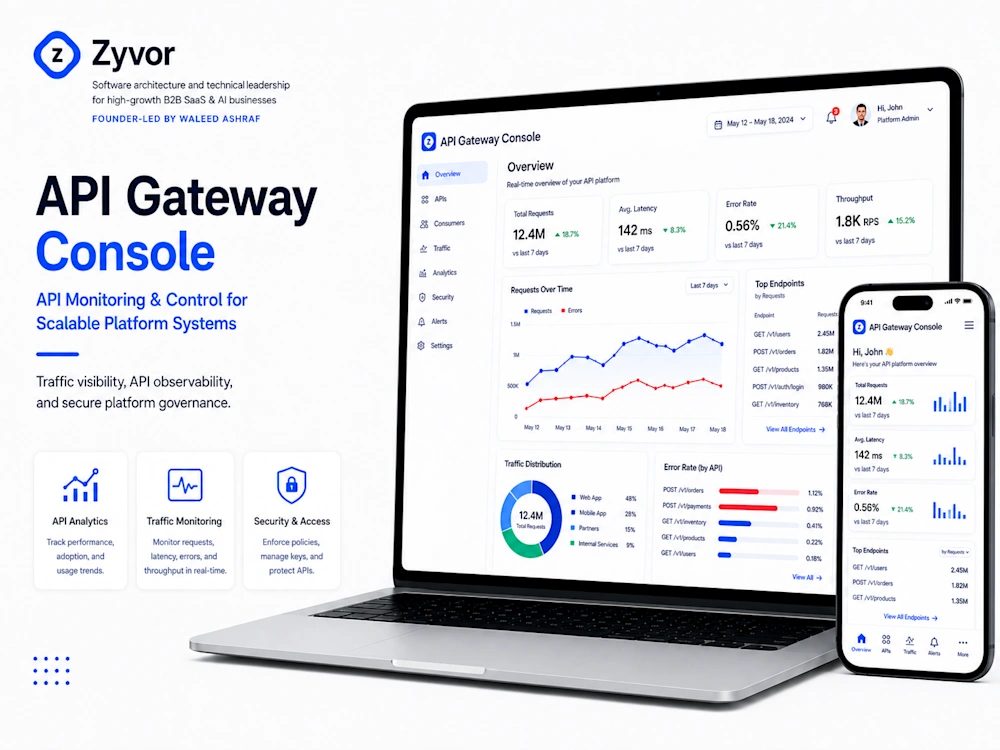
65 point-to-point scripts replaced with managed connectors. New employee provisioning across all systems dropped from 3 days to 15 minutes. Integration maintenance from 20+ hours/week to under 2 This is the kind of delivery leverage Zyvor looks for: fewer bottlenecks, clearer ownership, and better execution rhythm.
Architecture handoff
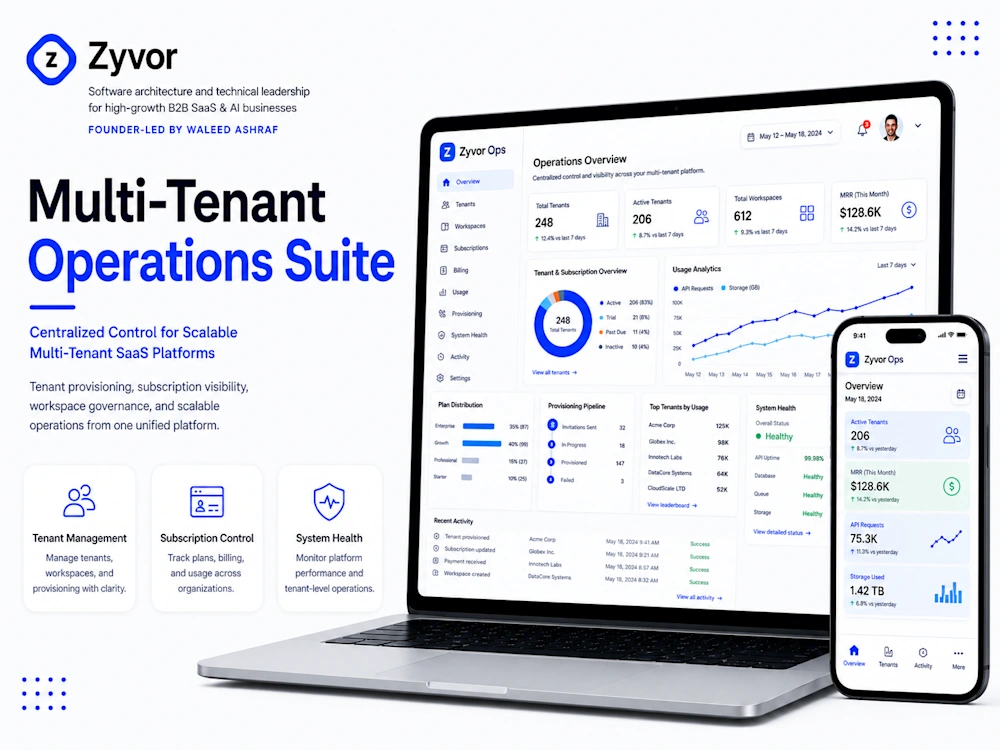
The project covered Node.js, TypeScript, PostgreSQL, Redis, React while keeping the handoff focused on maintainability, future change, and leadership clarity instead of isolated implementation tasks.
Best-fit conversation
A similar engagement usually starts with the current bottleneck, the architecture decision that feels stuck, and the business risk that is becoming harder to ignore.